应用场景
在开发当中,会经常遇到排序的需求,比如根据时间倒序排序;根据价格降序排序;等等。有时还会遇到几种维度的排序。一般的,这种排序规则都会在数据库层面处理好顺序再返回给应用服务,order by 语句就可以按照某个字段或者某几个字段倒序(desc),正序(asc)排序
例子
现在有张表,记录我高中时高二所有人的成绩
1
2
3
4
5
6
7
8
9
10
11
12
|
CREATE TABLE `student_grade` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',
`class` int NOT NULL DEFAULT '1' COMMENT '班级',
`exam_code` varchar(16) NOT NULL DEFAULT '' COMMENT '考号',
`name` varchar(64) NOT NULL DEFAULT '' COMMENT '姓名',
`language_score` int NOT NULL COMMENT '语文分数',
`math_score` int NOT NULL COMMENT '数学分数',
`english_score` int NOT NULL COMMENT '英语分数',
`total_score` int NOT NULL COMMENT '总分数',
PRIMARY KEY (`id`),
KEY `idx_class` (`class`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='成绩表';
|
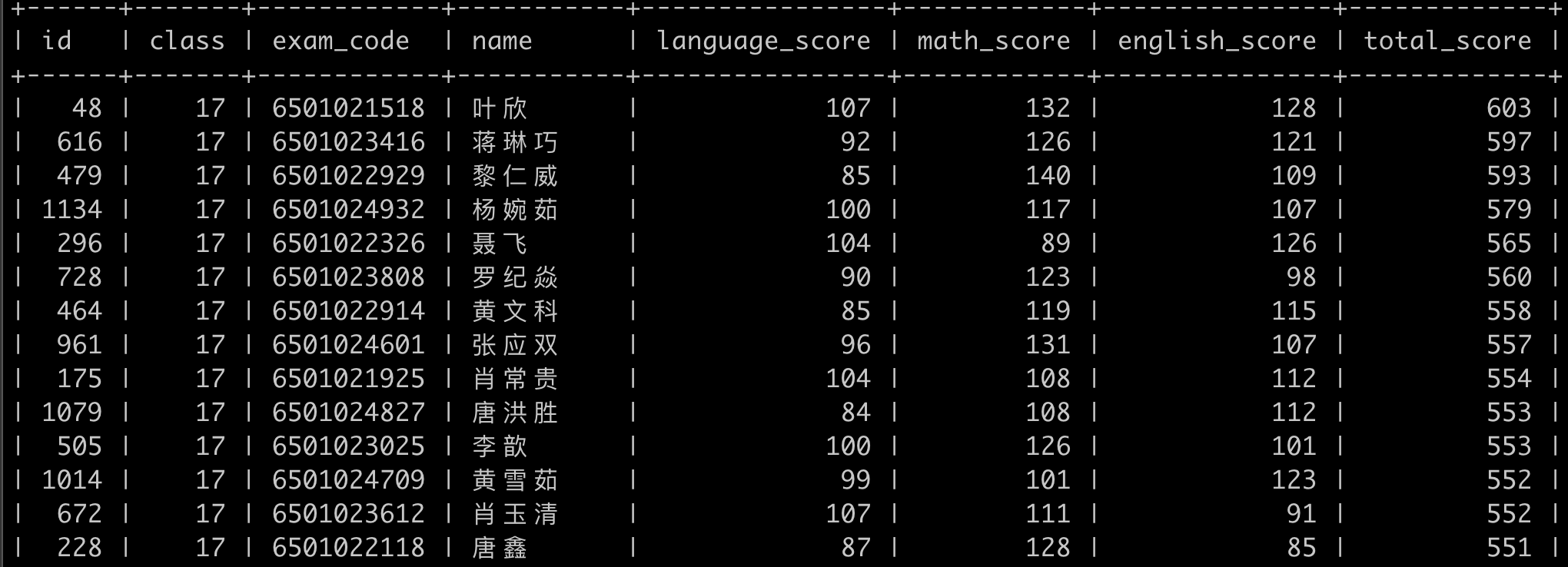
部分数据如下
现在我想看下我所处的班级(17)总成绩前10的都有哪些人,sql应该长这个样子
1
2
3
4
5
6
7
8
9
|
SELECT
*
FROM
student_grade
WHERE
class = 17
ORDER BY
total_score DESC
LIMIT 10;
|
由表结构可以看出,class是索引列,执行下explain看看这个排序语句有没有用索引
1
2
3
4
5
6
7
8
9
|
EXPLAIN SELECT
*
FROM
student_grade
WHERE
class = 17
ORDER BY
total_score DESC
LIMIT 10;
|

key表示使用到的索引Extra的Using filesort表示用到了排序
简易原理
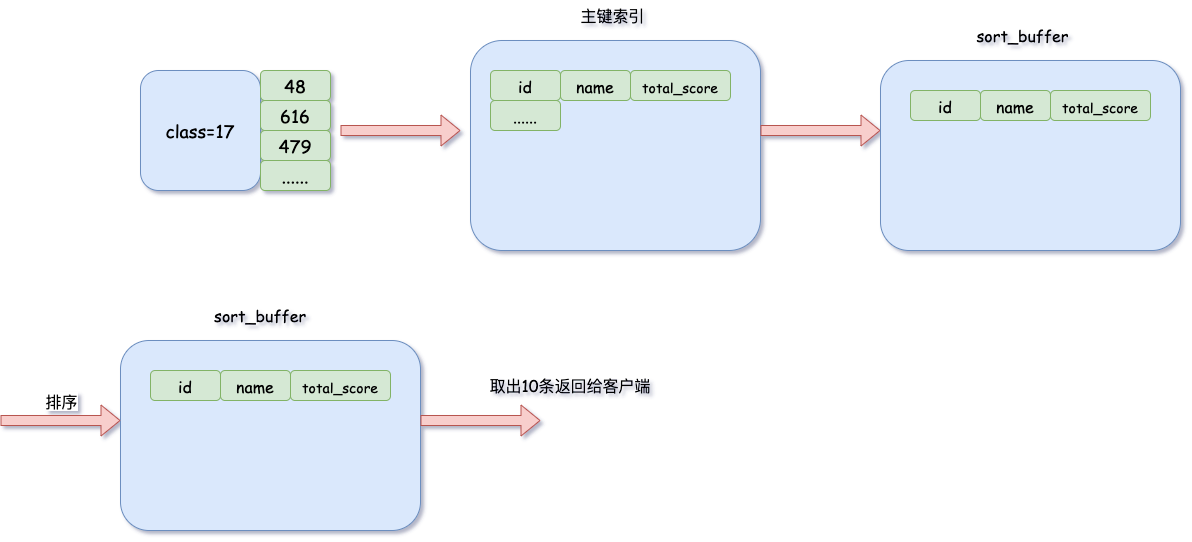
mysql会为每个查询的线程分配一块内存空间(sort buffer)用来排序。查询因子class作为索引列,可以很快的找到目标17班的数据
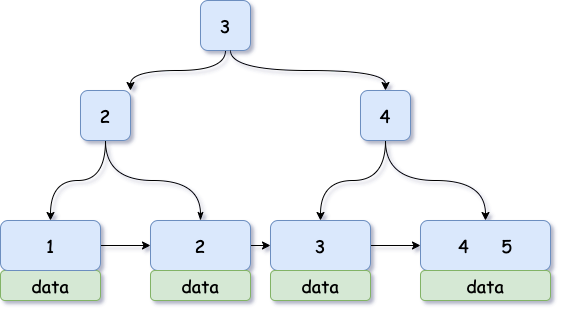
根据BPlusTree这个网站画出了class的索引树,绿色的数据域是数据的主键id 。还有一棵id的索引树,叶子节点存储了完整的数据。
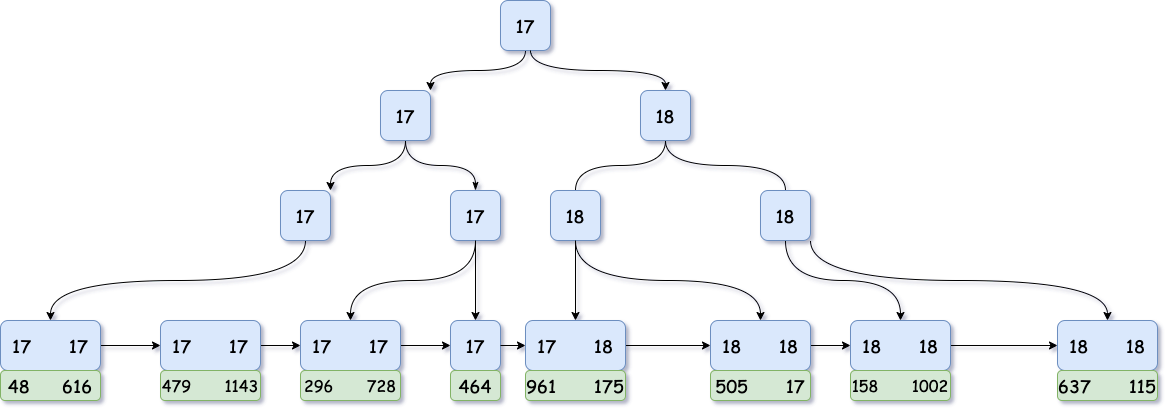
主键索引树
那么上述例子的排序流程:
- 根据
class的索引找到17对应的id集合
- 根据
id集合到主键索引树中找到对应的字段(回表操作)
- 把所需字段放入
sort_buffer中,根据total_score排序
- 按照排序结果取10条返回给客户端
如果所需要的字段全放进sort_buffer ,有可能sort_buffer放不下,这个时候需要文件辅助排序了
文件辅助排序
sort_buffer的大小是由sort_buffer_size控制的。如果要排序的数据小于sort_buffer_size,排序在sort_buffer 内存中完成,如果要排序的数据大于sort_buffer_size,则借助磁盘文件来进行排序。下面的sql可以帮助我们查看是否用到文件辅助排序
1
2
3
|
set optimizer_trace = "enabled=on";
select * from student_grade where class =17 order by total_score desc limit 10;
select * from information_schema.optimizer_trace
|
查看sort_buffer_size
1
|
show variables like 'sort_buffer_size';
|
如果排序的数据比这个值大,mysql会使用文件辅助排序(外部排序)。
- 从
id索引树中取出数据放入sort_buffer,最大程度占用sort_buffer,开始排序,放入一个临时的文件中
- 重复第一步骤,知道数据完全取出,在把有序的小文件合并成有序的大文件
rowid 排序
sort_buffer不够用,可以从另一种角度考虑问题。比如可以只需要查询用于排序的字段和主键id放进sort_buffer,排好序后再通过id回表取出想要的字段,这就是rowid排序。而控制是否使用rowid排序,有个参数max_length_for_sort_data,表示单行字段的长度,如果单行字段长度大于这个参数的值,就会使用rowid排序。
1
2
|
show variables like 'max_length_for_sort_data';
# max_length_for_sort_data 4096
|
上文的例子中全部字段的长度加起来小于4096,可以故意改小一点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
SET max_length_for_sort_data = 32;
SELECT
*
FROM
student_grade
WHERE
class = 17
ORDER BY
total_score DESC
LIMIT 10;
select * from information_schema.optimizer_trace
|
trace 中有 "rowid_ordered": true 表示使用的是rowid 排序
order by 注意点
查询没有where条件,order by 的字段不需要加索引,加了索引也是全表扫描,如果有limit是有可能用到索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
ALTER table
student_grade
ADD
INDEX idx_total_scores(total_score);
EXPLAIN SELECT
*
FROM
student_grade
ORDER BY
total_score DESC
# 用到了索引
EXPLAIN SELECT
*
FROM
student_grade
ORDER BY
total_score DESC limit 1
|
Note
如果查询的字段就是索引列的字段,那么排序就会用到索引
order by 优化
索引列本身就有顺序,可以利用这个特性将class和toal_score 做成联合索引
1
2
3
4
5
6
7
8
9
10
11
|
ALTER table
student_grade
ADD
INDEX idx_class_total_score(class,total_score );
EXPLAIN SELECT
*
FROM
student_grade WHERE class=17
ORDER BY
total_score DESC
|
这样做就可以少一次回表。
但如果查询语句有in并且是多个值。还是会用到排序,这是因为单看17班是有序加入了18班,总成绩就需要重新排序
1
2
3
4
5
6
|
EXPLAIN SELECT
*
FROM
student_grade WHERE class in (17,18)
ORDER BY
total_score DESC
|