// /usr/local/go/src/runtime/map.go
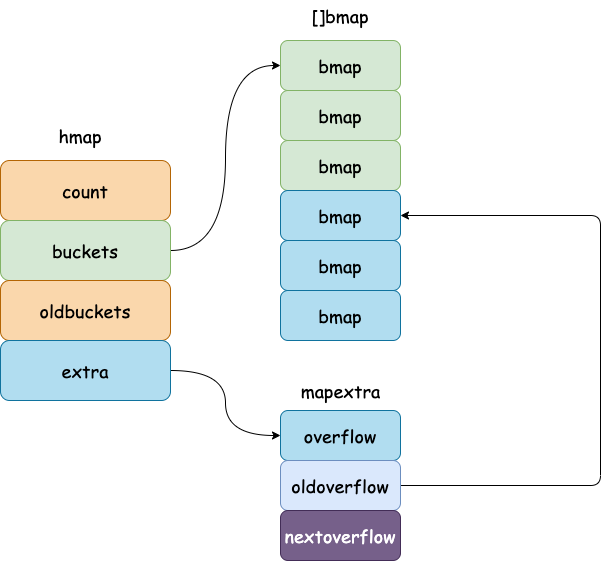
typehmapstruct{// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
countint// # live cells == size of map. Must be first (used by len() builtin)
flagsuint8Buint8// log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflowuint16// approximate number of overflow buckets; see incrnoverflow for details
hash0uint32// hash seed
bucketsunsafe.Pointer// array of 2^B Buckets. may be nil if count==0.
oldbucketsunsafe.Pointer// previous bucket array of half the size, non-nil only when growing
nevacuateuintptr// progress counter for evacuation (buckets less than this have been evacuated)
extra*mapextra// optional fields
}
mapextra
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
typemapextrastruct{// If both key and elem do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and elem do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow*[]*bmapoldoverflow*[]*bmap// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow*bmap}
// /usr/local/go/src/runtime/map.go
funcmapaccess1(t*maptype,h*hmap,keyunsafe.Pointer)unsafe.Pointer{ifraceenabled&&h!=nil{callerpc:=getcallerpc()pc:=abi.FuncPCABIInternal(mapaccess1)racereadpc(unsafe.Pointer(h),callerpc,pc)raceReadObjectPC(t.key,key,callerpc,pc)}ifmsanenabled&&h!=nil{msanread(key,t.key.size)}ifasanenabled&&h!=nil{asanread(key,t.key.size)}ifh==nil||h.count==0{ift.hashMightPanic(){t.hasher(key,0)// see issue 23734
}returnunsafe.Pointer(&zeroVal[0])}ifh.flags&hashWriting!=0{throw("concurrent map read and map write")}hash:=t.hasher(key,uintptr(h.hash0))m:=bucketMask(h.B)b:=(*bmap)(add(h.buckets,(hash&m)*uintptr(t.bucketsize)))ifc:=h.oldbuckets;c!=nil{if!h.sameSizeGrow(){// There used to be half as many buckets; mask down one more power of two.
m>>=1}oldb:=(*bmap)(add(c,(hash&m)*uintptr(t.bucketsize)))if!evacuated(oldb){b=oldb}}top:=tophash(hash)bucketloop:for;b!=nil;b=b.overflow(t){fori:=uintptr(0);i<bucketCnt;i++{ifb.tophash[i]!=top{ifb.tophash[i]==emptyRest{breakbucketloop}continue}k:=add(unsafe.Pointer(b),dataOffset+i*uintptr(t.keysize))ift.indirectkey(){k=*((*unsafe.Pointer)(k))}ift.key.equal(key,k){e:=add(unsafe.Pointer(b),dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))ift.indirectelem(){e=*((*unsafe.Pointer)(e))}returne}}}returnunsafe.Pointer(&zeroVal[0])}
// /usr/local/go/src/runtime/map.go
funcmapaccess2(t*maptype,h*hmap,keyunsafe.Pointer)(unsafe.Pointer,bool){ifraceenabled&&h!=nil{callerpc:=getcallerpc()pc:=abi.FuncPCABIInternal(mapaccess2)racereadpc(unsafe.Pointer(h),callerpc,pc)raceReadObjectPC(t.key,key,callerpc,pc)}ifmsanenabled&&h!=nil{msanread(key,t.key.size)}ifasanenabled&&h!=nil{asanread(key,t.key.size)}ifh==nil||h.count==0{ift.hashMightPanic(){t.hasher(key,0)// see issue 23734
}returnunsafe.Pointer(&zeroVal[0]),false}ifh.flags&hashWriting!=0{throw("concurrent map read and map write")}hash:=t.hasher(key,uintptr(h.hash0))m:=bucketMask(h.B)b:=(*bmap)(add(h.buckets,(hash&m)*uintptr(t.bucketsize)))ifc:=h.oldbuckets;c!=nil{if!h.sameSizeGrow(){// There used to be half as many buckets; mask down one more power of two.
m>>=1}oldb:=(*bmap)(add(c,(hash&m)*uintptr(t.bucketsize)))if!evacuated(oldb){b=oldb}}top:=tophash(hash)bucketloop:for;b!=nil;b=b.overflow(t){fori:=uintptr(0);i<bucketCnt;i++{ifb.tophash[i]!=top{ifb.tophash[i]==emptyRest{breakbucketloop}continue}k:=add(unsafe.Pointer(b),dataOffset+i*uintptr(t.keysize))ift.indirectkey(){k=*((*unsafe.Pointer)(k))}ift.key.equal(key,k){e:=add(unsafe.Pointer(b),dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))ift.indirectelem(){e=*((*unsafe.Pointer)(e))}returne,true}}}returnunsafe.Pointer(&zeroVal[0]),false}
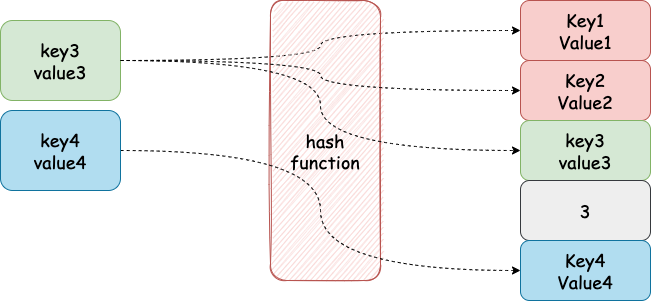
map 写操作
写操作在语法上形如:myMap["name"]="joker",对应的源代码func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer(/usr/local/go/src/runtime/map.go),这个函数非常长,逐个分析
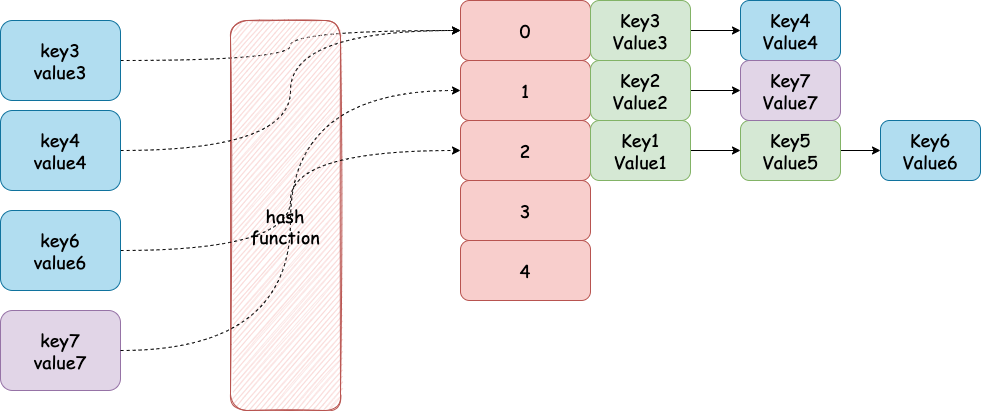
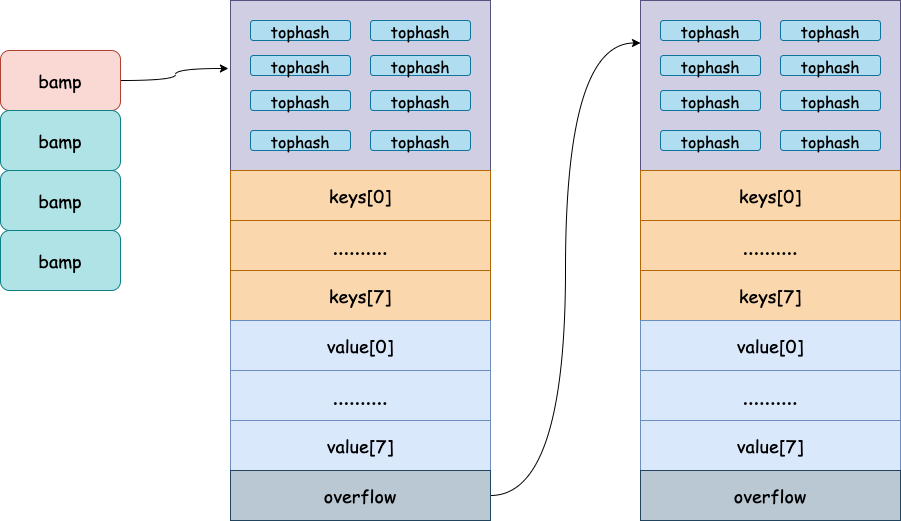
bucketloop:for{fori:=uintptr(0);i<bucketCnt;i++{ifb.tophash[i]!=top{ifisEmpty(b.tophash[i])&&inserti==nil{inserti=&b.tophash[i]insertk=add(unsafe.Pointer(b),dataOffset+i*uintptr(t.keysize))elem=add(unsafe.Pointer(b),dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))}ifb.tophash[i]==emptyRest{breakbucketloop}continue}k:=add(unsafe.Pointer(b),dataOffset+i*uintptr(t.keysize))ift.indirectkey(){k=*((*unsafe.Pointer)(k))}if!t.key.equal(key,k){continue}// already have a mapping for key. Update it.
ift.needkeyupdate(){typedmemmove(t.key,k,key)}elem=add(unsafe.Pointer(b),dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))gotodone}ovf:=b.overflow(t)ifovf==nil{break}b=ovf}
map 的扩容
map 的删除
map 的优化
内存泄露
go 的map随着长时间的系统运行,其占用的内存只增不减。其原因是因为在map中的bucket会随着容量不足进行扩容,但不会因为delete操作而缩小容量,而本身的bucket需要占用内存的