// usr/local/go/src/sync/mutex.go
// A Locker represents an object that can be locked and unlocked.
typeLockerinterface{Lock()Unlock()}
在golang源码中,Lock长这个样子
1
2
3
4
5
6
7
8
9
10
11
12
///usr/local/go/src/sync/mutex.go
func(m*Mutex)Lock(){// Fast path: grab unlocked mutex.
ifatomic.CompareAndSwapInt32(&m.state,0,mutexLocked){ifrace.Enabled{race.Acquire(unsafe.Pointer(m))}return}// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()}
// usr/local/go/src/sync/mutex.go
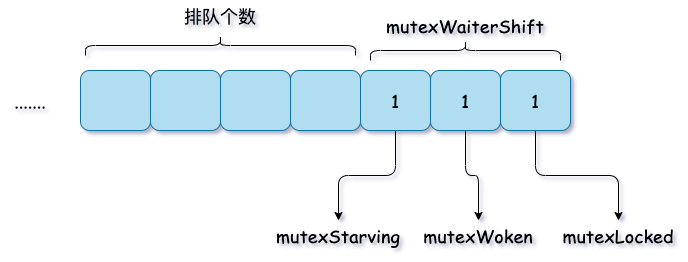
func(m*Mutex)lockSlow(){varwaitStartTimeint64starving:=falseawoke:=falseiter:=0old:=m.statefor{// Don't spin in starvation mode, ownership is handed off to waiters
// so we won't be able to acquire the mutex anyway.
ifold&(mutexLocked|mutexStarving)==mutexLocked&&runtime_canSpin(iter){// Active spinning makes sense.
// Try to set mutexWoken flag to inform Unlock
// to not wake other blocked goroutines.
if!awoke&&old&mutexWoken==0&&old>>mutexWaiterShift!=0&&atomic.CompareAndSwapInt32(&m.state,old,old|mutexWoken){awoke=true}runtime_doSpin()iter++old=m.statecontinue}
//usr/local/go/src/sync/mutex.go
new:=old// Don't try to acquire starving mutex, new arriving goroutines must queue.
ifold&mutexStarving==0{new|=mutexLocked}ifold&(mutexLocked|mutexStarving)!=0{new+=1<<mutexWaiterShift}// The current goroutine switches mutex to starvation mode.
// But if the mutex is currently unlocked, don't do the switch.
// Unlock expects that starving mutex has waiters, which will not
// be true in this case.
ifstarving&&old&mutexLocked!=0{new|=mutexStarving}ifawoke{// The goroutine has been woken from sleep,
// so we need to reset the flag in either case.
ifnew&mutexWoken==0{throw("sync: inconsistent mutex state")}new&^=mutexWoken}
// usr/local/go/src/sync/mutex.go
// Unlock unlocks m.
// It is a run-time error if m is not locked on entry to Unlock.
//
// A locked Mutex is not associated with a particular goroutine.
// It is allowed for one goroutine to lock a Mutex and then
// arrange for another goroutine to unlock it.
func(m*Mutex)Unlock(){ifrace.Enabled{_=m.staterace.Release(unsafe.Pointer(m))}// Fast path: drop lock bit.
new:=atomic.AddInt32(&m.state,-mutexLocked)ifnew!=0{// Outlined slow path to allow inlining the fast path.
// To hide unlockSlow during tracing we skip one extra frame when tracing GoUnblock.
m.unlockSlow(new)}}
typeRWMutexstruct{wMutex// held if there are pending writers
writerSemuint32// semaphore for writers to wait for completing readers
readerSemuint32// semaphore for readers to wait for completing writers
readerCountint32// number of pending readers
readerWaitint32// number of departing readers
}
// /usr/local/go/src/sync/rwmutex.go
func(rw*RWMutex)Lock(){// First, resolve competition with other writers.
rw.w.Lock()// Announce to readers there is a pending writer.
r:=atomic.AddInt32(&rw.readerCount,-rwmutexMaxReaders)+rwmutexMaxReaders// Wait for active readers.
ifr!=0&&atomic.AddInt32(&rw.readerWait,r)!=0{runtime_SemacquireMutex(&rw.writerSem,false,0)}}